
No, they are not. But they have a number of similarities that might be unexpected when you first learn a certain algorithm, such as Word2Vec or GloVe. This post is a summary of a series of papers that I found in the latest years, which show aspects common to word embedding methods that have been developed independently.
Before Word2vec: count-based models
We can create compact representations of words from corpora without developing complex algorithms for that task. Many existing ideas have been used, mostly based on counting word frequencies. The easiest would be matrix factorization: given the matrix of words-documents, perform Singular Value Decomposition (SVD) and keep only the K largest singular values (for any K smaller than the number of documents), then you get a dense, compact representation of K dimensions for every word.

In the previous technique, we can replace the word frequencies by other association measures such as the tf-idf or the Pointwise Mutual Information (PMI), which is an Information Theory measure that says how likely it is to find an association between a word and a document, compared to random association. It has been used a lot by the NLP community.
Word2vec and GloVe
In 2013, a group of algorithms called Word2vec were developed at Google and changed the pace of word embeddings. Word2vec trains a neural network to predict the context of words, i.e. words that appear in the vicinity of words. It has two flavours depending on design decisions: Skip-Gram and Continuous Bag-of-words. The state-of-the-art Word2vec is usually considered Skip-Gram with Negative Sampling (SGNS), a specific implementation with some details that make it feasible to train accurately.
In 2014, the GloVe algorithm was developed at Stanford and entails a different method for word embeddings. Instead of using a neural network, it is posed as a least squares problem from the ratios of co-occurrence probabilities of words. The assumption is that ratios of co-occurrences discriminate better than raw co-occurrences. In practice, either GloVe or Word2vec can work better for a certain problem.
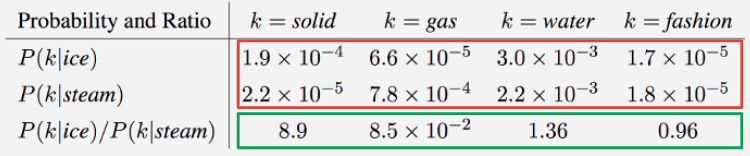
Source: GloVe paper.
Similarity #1: “Neural word embedding as implicit matrix factorization”
This paper by Levy and Goldberg in 2014 shows that Word2vec SGNS “is implicitly factorizing a word-context matrix, whose cells are the pointwise mutual information (PMI) of the respective word and context pairs, shifted by a global constant”. This means that, theoretically, SGNS is not different to the classic count-based models for word embeddings. In practice, the paper proposes when a method should be preferred over the other, which mainly depends on the dimensionality and the problem (in the end, word embeddings are usually a preprocess for a main task such as similarity, analogy, classification, etc; so the most important evaluation is how it helps in solving the main task).
Similarity #2: “Linking GloVe with Word2vec”
Talking again from a theoretical point of view (in practice, no method will replace all others in all problems with all data), this paper by Shi and Liu in 2014 shows that we could convert Skip-Gram into GloVe if we apply the following transformations:
- Optimize the global cost function instead of approximating it online with a neural network.
- Instead of using Negative Sampling, we discard normalization factors.
- Instead of subsampling frequent words, we use GloVe’s weighting function.
From these points, I conclude that both methods are solving a set of decisions (optimization, normalization, frequency weighting) with different tools, but the decisions are the same and this should be remembered in future research on word embeddings, because it helps think outside the box and understand the problem from a more global perspective.
Similarity #3: The bias term
Going further with the conclusion presented above, Shi and Liu also show another resemblance between GloVe and SGNS. After the two algorithms converge in their experiments, there appears a Pearson’s correlation coefficient of 80% between GloVe’s bias terms and SGNS’ log(#w), i.e. the fixed terms for each word. Two different optimization formulas appear to have terms highly correlated, which should lead us to ask if both algorithms are more similar than we could think.
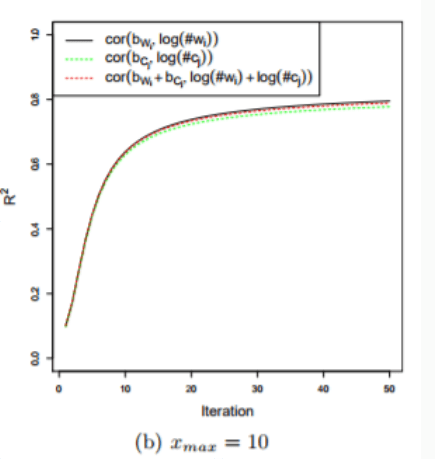
Source: Shi and Liu, 2014.
A unified framework for word embeddings?
After all I learned from the readings that I shared with you in this post, my question is whether we should start thinking of embeddings as a unified framework with a taxonomy of decisions for which several solutions have been found and implemented in the current methods, such as:
- What corpus statistics are we using? Word co-occurrences, ratio of word co-occurrences (like GloVe), tf-idf, PMI, shifted PMI (like SGNS does implicitly)… All have been used in different attempts to embed words into vectors.
- How are we regularizing word frequencies? Using a weighting function that underweights very common occurrences (like GloVe), subsampling words based on their frequency (like Word2vec), doing nothing…
- What is the training procedure? A neural network (like Word2vec), least squares optimization (like GloVe), matrix factorization… Besides, many neural network architectures exist as well as many other optimization problems.
- What are the word vectors created like? Are they symmetric for word and context? What types of similarities are they storing? How many dimensions do they have (and how this number affects their performance)? What is the size of the context window? Should the vectors be normalized?
- How to evaluate the embedding? Should the corpus be domain-specific or general? Should we do intrinsic or extrinsic evaluation? If extrinsic, what are the application tasks we should be testing our embeddings on?
I believe that this perspective should help develop new word embedding algorithms with better knowledge of what is being done and without reinventing the wheel.
